Fitting CensoredDistributions.jl modified distributions with Turing.jl
Introduction
What are we going to do in this exercise
We'll demonstrate how to use CensoredDistributions.jl in conjunction with Turing.jl for Bayesian inference of epidemiological delay distributions. We'll cover the following key points:
Defining a simple delay distribution model without observation processes.
Exploring the prior distribution of this model.
Defining a Bayesian model that incorporates double censoring and right truncation
Generating synthetic data from the model using fixed parameters
Fitting a naive model that ignores censoring
Fitting a model that accounts for secondary event censoring and truncation but not primary event censoring.
Fitting the full model that accounts for double censoring and right truncation.
Using improved weight conditioning with joint observations and fix() patterns
Demonstrating StatsBase.AbstractWeights integration patterns
What might I need to know before starting
This tutorial builds on the concepts introduced in Getting Started with CensoredDistributions.jl.
We sample with Mooncake forward-mode AD (AutoMooncakeForward); see Automatic differentiation backends for the support matrix and per-backend benchmarks.
Packages used
We use CairoMakie for plotting, Turing for probabilistic programming, FlexiChains for working with MCMC output, Chain.jl for data pipeline workflows, DataFramesMeta, Random, and StatsBase.
using DataFramesMeta
using Turing
using DynamicPPL
using Distributions
using Random
using CairoMakie, PairPlots
using StatsBase
using FlexiChains
using FlexiChains: Prefixed, parameters
using CensoredDistributions
using ADTypes: AutoMooncakeForward
import MooncakeGenerate synthetic data using Turing model simulation
We'll generate synthetic data by simulating from our Turing model with known true parameters. This approach ensures consistency between the data generation process and the model we'll use for inference, demonstrating how Turing models can be used for both simulation and fitting.
The proper Turing simulation approach:
Define a Turing model that incorporates double censoring and right truncation
Create a model instance with missing observations for simulation
Use DynamicPPL's
fixfunction to set parameters to their true valuesSample from the prior predictive distribution by calling the model as a function
Define the true parameters for generating synthetic data
We start by defining the number of samples and the true parameters of the lognormal.
n = 2000;
meanlog = 1.5;
sdlog = 0.75;Now we can define a lognormal distribution using Distributions.jl.
true_dist = LogNormal(meanlog, sdlog);For each individual we now sample a primary and secondary event window as well as a relative observation time (relative to their censored primary event).
Define a reusable submodel for the latent delay distribution
To avoid code duplication across our models, we define a submodel that encapsulates the latent delay distribution parameters. This pattern allows us to reuse the same prior structure across all our models:
@model function latent_delay_dist()
mu ~ Normal(1.0, 2.0);
sigma ~ truncated(Normal(0.5, 1); lower = 0.0)
return LogNormal(mu, sigma)
endlatent_delay_dist (generic function with 2 methods)and define a helper function to standardise our pairplot visualisations across all model fits. We sample with chain_type = VNChain to get a FlexiChains VNChain and wrap it in PairPlots.Series so we can overlay a PairPlots.Truth layer with the known values. The same helper works for both the plain latent_delay_dist() chain and chains where latent_delay_dist() has been used as a submodel (where parameters are automatically prefixed, e.g. dist.mu).
function plot_fit_with_truth(chain, truth_nt)
samples = NamedTuple{keys(truth_nt)}(
Tuple(vec(chain[Prefixed(k)]) for k in keys(truth_nt))
)
return pairplot(
PairPlots.Series(samples),
PairPlots.Truth(truth_nt, label = "True Values")
)
endplot_fit_with_truth (generic function with 1 method)Prior predictive checks using pairplot
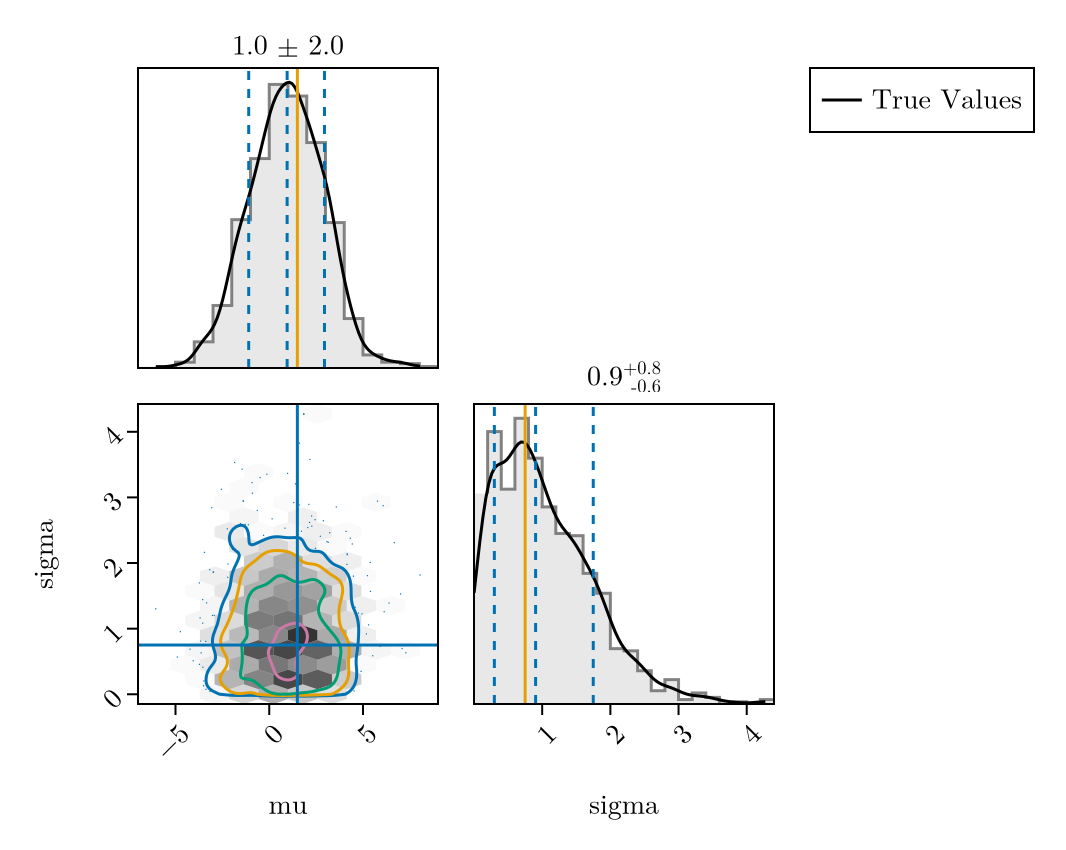
First, let's visualise the prior predictive distribution by sampling from the instantiated model with uninformative priors and comparing against our true parameters. This shows what the model believes before seeing any data.
Random.seed!(123);
# Sample from the latent delay distribution prior
latent_prior_samples = sample(
latent_delay_dist(), Prior(), 1000; chain_type = VNChain
)
# Visualise the prior distribution
plot_fit_with_truth(
latent_prior_samples,
(; mu = meanlog, sigma = sdlog)
)
Define the double censored model for simulation and fitting
Now we define our full model that incorporates double censoring and right truncation. This model uses the latent_delay_dist() submodel via to_submodel() to include the delay distribution parameters. It also uses our double_interval_censored() function to define each double censored and right truncated delay:
@model function CensoredDistributions_model(
pwindow_bounds, swindow_bounds, obs_time_bounds
)
pwindows ~ product_distribution(
[DiscreteUniform(pw[1], pw[2]) for pw in pwindow_bounds]
)
swindows ~ product_distribution(
[DiscreteUniform(sw[1], sw[2]) for sw in swindow_bounds]
)
obs_times ~ product_distribution(
[DiscreteUniform(ot[1], ot[2]) for ot in obs_time_bounds]
)
dist ~ to_submodel(latent_delay_dist())
pcens_dists = map(
pwindows, obs_times, swindows
) do pw, D, sw
pe = Uniform(0, pw)
double_interval_censored(
dist;
primary_event = pe,
upper = D,
interval = sw
)
end
obs ~ weight(pcens_dists)
endCensoredDistributions_model (generic function with 2 methods)We also need to define our simulated observation window bounds for each observed delay as well as the bounds on the amount of censored time in which events have been observed (required to adjust for truncation). We will then combine these bounds with the model in order to simulate data.
bounds_df = DataFrame(
pwindow_bounds = fill((1, 3), n),
swindow_bounds = fill((1, 3), n),
obs_time_bounds = fill((8, 12), n)
);Simulate from the double censored distribution for each
individual
Using the double censored model, we simulate data by sampling from the model using known true parameters. We use Turing's simulation approach with DynamicPPL's fix function to set parameters to their true values and sample from the prior predictive distribution. This means we can use the same model for simulation and inference.
We first create the base model which only specifies bounds to sample for the observations processes. We'll use this for both simulation and fitting:
base_model = @with bounds_df begin
CensoredDistributions_model(
:pwindow_bounds,
:swindow_bounds,
:obs_time_bounds
)
endDynamicPPL.Model{typeof(Main.var"Main".CensoredDistributions_model), (:pwindow_bounds, :swindow_bounds, :obs_time_bounds), (), (), Tuple{Vector{Tuple{Int64, Int64}}, Vector{Tuple{Int64, Int64}}, Vector{Tuple{Int64, Int64}}}, Tuple{}, DynamicPPL.DefaultContext, false}(Main.var"Main".CensoredDistributions_model, (pwindow_bounds = [(1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3) … (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3)], swindow_bounds = [(1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3) … (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3)], obs_time_bounds = [(8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12) … (8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12)]), NamedTuple(), DynamicPPL.DefaultContext())For simulation, fix the distribution parameters to known true values:
simulation_model = fix(
base_model,
(
@varname(dist.mu) => meanlog,
@varname(dist.sigma) => sdlog
)
)DynamicPPL.Model{typeof(Main.var"Main".CensoredDistributions_model), (:pwindow_bounds, :swindow_bounds, :obs_time_bounds), (), (), Tuple{Vector{Tuple{Int64, Int64}}, Vector{Tuple{Int64, Int64}}, Vector{Tuple{Int64, Int64}}}, Tuple{}, DynamicPPL.CondFixContext{DynamicPPL.Fix, DynamicPPL.VarNamedTuples.VarNamedTuple{(:dist,), Tuple{DynamicPPL.VarNamedTuples.VarNamedTuple{(:mu, :sigma), Tuple{Float64, Float64}}}}, DynamicPPL.DefaultContext}, false}(Main.var"Main".CensoredDistributions_model, (pwindow_bounds = [(1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3) … (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3)], swindow_bounds = [(1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3) … (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3), (1, 3)], obs_time_bounds = [(8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12) … (8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12), (8, 12)]), NamedTuple(), CondFixContext{DynamicPPL.Fix}(VarNamedTuple(dist = VarNamedTuple(mu = 1.5, sigma = 0.75),), DynamicPPL.DefaultContext()))Now we can sample from the model using rand to get simulated observations with their observation windows and relative observation time:
simulated_data = @chain simulation_model begin
rand
NamedTuple
DataFrame
end;Visualise the simulated data
To make handling the data easier and later to speed up our models we first create a dataframe with the data we just generated, aggregated to unique combinations and count occurrences.
simulated_counts = @chain simulated_data begin
@transform :obs_upper = :obs .+ :swindows
@groupby All()
@combine :n = length(:pwindows)
end;Now let's compare the samples with and without double interval censoring to the true distribution. First let's calculate the empirical CDF:
empirical_cdf_obs = @with(simulated_counts, ecdf(:obs, weights = :n));
# Create a sequence of x values for the theoretical CDF
x_seq = @with simulated_counts begin
range(
minimum(:obs),
stop = maximum(:obs) + 2,
length = 100
);
end;
# Calculate theoretical CDF using true log-normal distribution
theoretical_cdf = @chain x_seq begin
cdf.(true_dist, _)
end;
# Generate uncensored samples from the true distribution
uncensored_samples = rand(true_dist, n);
empirical_cdf_uncensored = ecdf(uncensored_samples);
f = Figure()
ax = Axis(
f[1, 1],
title = "Censored vs Uncensored vs Theoretical CDF",
ylabel = "Cumulative Probability",
xlabel = "Delay"
)
scatter!(
ax,
x_seq,
empirical_cdf_obs.(x_seq),
label = "Empirical CDF (Censored)",
color = :blue
)
scatter!(
ax,
x_seq,
empirical_cdf_uncensored.(x_seq),
label = "Empirical CDF (Uncensored)",
color = :red,
marker = :cross
)
lines!(
ax, x_seq, theoretical_cdf,
label = "Theoretical CDF",
color = :black, linewidth = 2
)
vlines!(
ax, [mean(simulated_data.obs)],
color = :blue, linestyle = :dash,
label = "Censored mean", linewidth = 2
)
vlines!(
ax, [mean(uncensored_samples)],
color = :red, linestyle = :dash,
label = "Uncensored mean", linewidth = 2
)
vlines!(
ax, [mean(true_dist)],
linestyle = :dash,
label = "Theoretical mean",
color = :black, linewidth = 2
)
axislegend(position = :rb)
f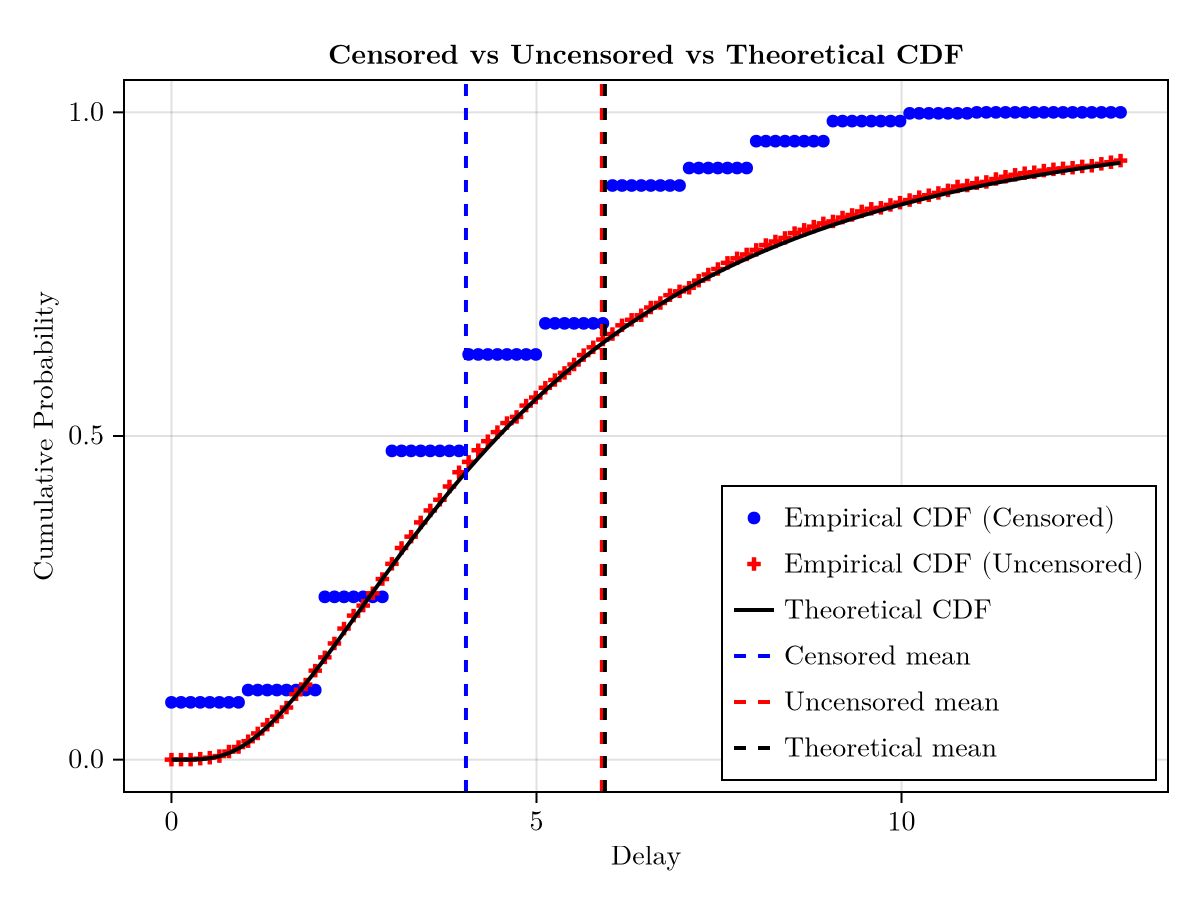
Fitting a naive model using Turing
We'll now fit a naive model that ignores the censoring process. This model treats the observed delay data as if it came directly from the uncensored delay distribution, providing a baseline for comparison.
@model function naive_model()
dist ~ to_submodel(latent_delay_dist())
obs ~ weight(dist)
endnaive_model (generic function with 2 methods)Now let's instantiate and condition this model using weighted observations. We use a small constant to avoid issues at zero (a hint that this model is misspecified) and condition directly using NamedTuple format (values = values, weights = counts) which enables joint observation conditioning.
naive_mdl = @with simulated_counts begin
condition(
naive_model(),
obs = (values = :obs .+ 1e-6, weights = :n)
)
endDynamicPPL.Model{typeof(Main.var"Main".naive_model), (), (), (), Tuple{}, Tuple{}, DynamicPPL.CondFixContext{DynamicPPL.Condition, DynamicPPL.VarNamedTuples.VarNamedTuple{(:obs,), Tuple{@NamedTuple{values::Vector{Float64}, weights::Vector{Int64}}}}, DynamicPPL.DefaultContext}, false}(Main.var"Main".naive_model, NamedTuple(), NamedTuple(), CondFixContext{DynamicPPL.Condition}(VarNamedTuple(obs = (values = [8.000001, 3.000001, 6.000001, 3.000001, 9.000001, 1.0e-6, 4.000001, 7.000001, 6.000001, 4.000001, 6.000001, 2.000001, 6.000001, 4.000001, 8.000001, 4.000001, 3.000001, 6.000001, 3.000001, 7.000001, 8.000001, 2.000001, 4.000001, 2.000001, 6.000001, 2.000001, 6.000001, 6.000001, 1.000001, 2.000001, 5.000001, 4.000001, 2.000001, 4.000001, 5.000001, 6.000001, 6.000001, 4.000001, 1.0e-6, 3.000001, 3.000001, 3.000001, 1.0e-6, 3.000001, 10.000001, 6.000001, 4.000001, 2.000001, 2.000001, 2.000001, 3.000001, 3.000001, 7.000001, 2.000001, 3.000001, 2.000001, 1.0e-6, 2.000001, 8.000001, 6.000001, 3.000001, 9.000001, 8.000001, 3.000001, 3.000001, 3.000001, 3.000001, 4.000001, 4.000001, 3.000001, 8.000001, 3.000001, 4.000001, 10.000001, 2.000001, 6.000001, 6.000001, 3.000001, 9.000001, 5.000001, 5.000001, 2.000001, 4.000001, 1.000001, 6.000001, 6.000001, 5.000001, 5.000001, 1.0e-6, 1.0e-6, 6.000001, 1.0e-6, 3.000001, 6.000001, 4.000001, 6.000001, 9.000001, 4.000001, 6.000001, 2.000001, 3.000001, 1.0e-6, 7.000001, 5.000001, 4.000001, 2.000001, 3.000001, 1.0e-6, 6.000001, 6.000001, 4.000001, 3.000001, 4.000001, 6.000001, 6.000001, 3.000001, 1.0e-6, 7.000001, 4.000001, 4.000001, 6.000001, 9.000001, 2.000001, 3.000001, 6.000001, 3.000001, 6.000001, 1.000001, 10.000001, 8.000001, 9.000001, 1.0e-6, 6.000001, 4.000001, 2.000001, 4.000001, 8.000001, 4.000001, 8.000001, 1.0e-6, 3.000001, 6.000001, 2.000001, 8.000001, 5.000001, 4.000001, 1.0e-6, 5.000001, 4.000001, 1.000001, 7.000001, 4.000001, 9.000001, 6.000001, 2.000001, 1.0e-6, 5.000001, 6.000001, 2.000001, 8.000001, 2.000001, 8.000001, 2.000001, 1.000001, 1.0e-6, 6.000001, 3.000001, 4.000001, 6.000001, 6.000001, 9.000001, 9.000001, 7.000001, 8.000001, 1.0e-6, 8.000001, 6.000001, 10.000001, 4.000001, 1.0e-6, 4.000001, 8.000001, 2.000001, 1.0e-6, 6.000001, 9.000001, 2.000001, 7.000001, 9.000001, 2.000001, 6.000001, 3.000001, 5.000001, 4.000001, 6.000001, 8.000001, 5.000001, 5.000001, 7.000001, 9.000001, 2.000001, 6.000001, 6.000001, 6.000001, 1.0e-6, 1.0e-6, 5.000001, 1.000001, 7.000001, 2.000001, 6.000001, 7.000001, 9.000001, 7.000001, 1.0e-6, 10.000001, 1.0e-6, 8.000001, 7.000001, 1.000001, 2.000001, 1.000001, 3.000001, 1.000001, 1.0e-6, 1.0e-6, 9.000001, 8.000001, 10.000001, 1.0e-6, 6.000001, 9.000001, 8.000001, 10.000001, 10.000001, 8.000001, 7.000001, 2.000001, 6.000001, 6.000001, 5.000001, 1.0e-6, 1.000001, 1.0e-6, 10.000001, 1.000001, 11.000001, 1.0e-6, 8.000001, 9.000001, 1.000001, 1.0e-6, 1.000001, 1.000001, 11.000001, 1.0e-6, 9.000001, 1.0e-6], weights = [3, 7, 6, 13, 4, 11, 16, 2, 18, 3, 12, 22, 2, 12, 3, 9, 22, 20, 28, 4, 1, 22, 16, 10, 7, 20, 10, 11, 4, 17, 7, 9, 11, 15, 5, 16, 17, 16, 15, 22, 9, 3, 8, 26, 4, 14, 14, 10, 15, 14, 20, 8, 2, 9, 19, 4, 2, 6, 6, 9, 24, 9, 4, 11, 22, 20, 20, 21, 16, 24, 7, 4, 5, 2, 10, 7, 11, 13, 3, 3, 7, 13, 6, 6, 4, 14, 5, 11, 3, 16, 15, 9, 19, 11, 6, 13, 8, 15, 6, 6, 8, 11, 6, 6, 7, 11, 6, 1, 17, 9, 5, 20, 3, 9, 21, 24, 5, 6, 10, 8, 10, 6, 6, 14, 7, 12, 8, 1, 6, 7, 3, 7, 9, 5, 3, 21, 7, 5, 6, 9, 8, 5, 7, 2, 6, 6, 9, 8, 6, 5, 4, 7, 3, 17, 8, 9, 8, 6, 5, 5, 5, 2, 9, 2, 5, 13, 6, 11, 1, 3, 5, 1, 7, 4, 4, 2, 9, 2, 9, 2, 11, 9, 8, 11, 6, 1, 7, 3, 3, 10, 8, 10, 5, 5, 5, 1, 5, 7, 2, 4, 4, 3, 3, 12, 1, 2, 9, 4, 7, 11, 5, 3, 3, 3, 12, 2, 3, 6, 2, 1, 2, 4, 9, 2, 3, 4, 2, 3, 1, 4, 4, 3, 1, 4, 1, 3, 3, 3, 4, 9, 4, 2, 3, 4, 2, 1, 1, 2, 1, 1, 2, 1, 1, 2, 2, 1, 3, 1]),), DynamicPPL.DefaultContext()))Now let's fit the conditioned model using the joint observation pattern (values = values, weights = counts).
naive_fit = sample(
naive_mdl,
NUTS(; adtype = AutoMooncakeForward()),
MCMCThreads(), 500, 4;
chain_type = VNChain
);
summarystats(naive_fit)╭─FlexiSummary (9 statistics) ─────────────────────────────────────────────────╮
│ iter collapsed │
│ chain collapsed │
│ ↓ stat = [mean, std, mcse, ess_bulk, ess_tail, rhat, q5, q50, q95] │
│ │
│ Parameters (2) ── AbstractPPL.VarName │
│ Float64 dist.mu, dist.sigma │
│ │
│ Extras (14) │
│ Float64 n_steps, is_accept, acceptance_rate, log_density, │
│ hamiltonian_energy, hamiltonian_energy_error, │
│ max_hamiltonian_energy_error, tree_depth, numerical_error, │
│ step_size, nom_step_size, logprior, loglikelihood, logjoint │
│ │
│ Summary │
│ param mean std mcse ess_bulk ess_tail rhat … │
│ dist.mu 0.0306 0.0971 0.0022 1921.4827 1482.4949 0.9997 … │
│ dist.sigma 4.3256 0.0695 0.0015 2039.7532 1655.0034 0.9998 … │
╰──────────────────────────────────────────────────────────────────────────────╯And let's visualise the posterior alongside the true values:
plot_fit_with_truth(
naive_fit,
(; mu = meanlog, sigma = sdlog)
)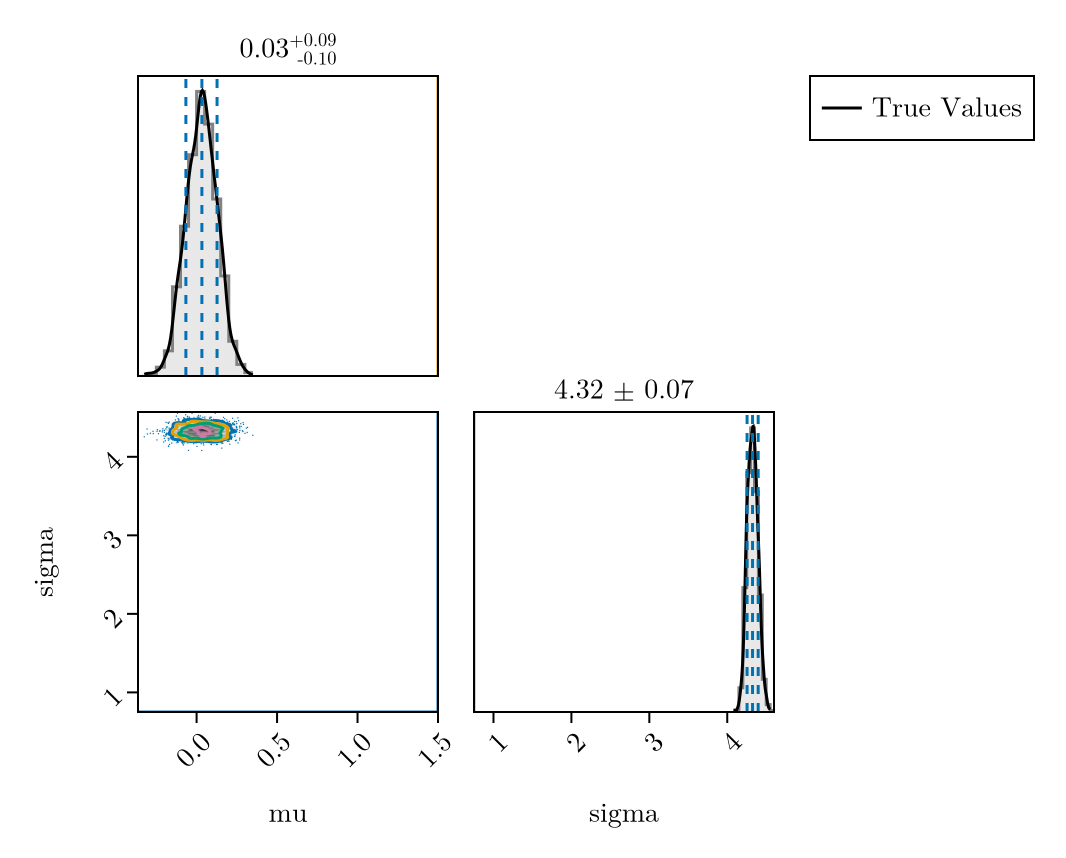
We see that the model has converged and the diagnostics look good. However, just from the model posterior summary we see that we might not be very happy with the fit. mu is smaller than the target 1.5 and sigma is larger than the target 0.75.
Fitting a truncation-adjusted interval model
Now let's fit an intermediate model that accounts for interval censoring and right truncation but ignores the primary censoring process. This provides a comparison point between the naive model and the full model.
@model function interval_only_model(
swindow_bounds, obs_time_bounds
)
swindows ~ product_distribution(
[Uniform(sw[1], sw[2]) for sw in swindow_bounds]
)
obs_times ~ product_distribution(
[Uniform(ot[1], ot[2]) for ot in obs_time_bounds]
)
dist ~ to_submodel(latent_delay_dist())
icens_dists = map(obs_times, swindows) do D, sw
truncated(
interval_censored(dist, sw), upper = D
)
end
obs ~ weight(icens_dists)
return obs
endinterval_only_model (generic function with 2 methods)Create the interval-only model with bounds, fix the window parameters, and condition on observations
interval_only_mdl = @with simulated_counts begin
@chain interval_only_model(
bounds_df.swindow_bounds,
bounds_df.obs_time_bounds
) begin
fix((
@varname(swindows) => :swindows,
@varname(obs_times) => :obs_times
))
condition(
obs = (values = :obs, weights = :n)
)
end
end;Fit the interval-only model (Note: Turing.jl supports a wide range of fitting methods but here we use the No-U-turn sampler):
interval_only_fit = sample(
interval_only_mdl,
NUTS(; adtype = AutoMooncakeForward()),
MCMCThreads(), 500, 4;
chain_type = VNChain
);
summarystats(interval_only_fit)╭─FlexiSummary (9 statistics) ─────────────────────────────────────────────────╮
│ iter collapsed │
│ chain collapsed │
│ ↓ stat = [mean, std, mcse, ess_bulk, ess_tail, rhat, q5, q50, q95] │
│ │
│ Parameters (2) ── AbstractPPL.VarName │
│ Float64 dist.mu, dist.sigma │
│ │
│ Extras (14) │
│ Float64 n_steps, is_accept, acceptance_rate, log_density, │
│ hamiltonian_energy, hamiltonian_energy_error, │
│ max_hamiltonian_energy_error, tree_depth, numerical_error, │
│ step_size, nom_step_size, logprior, loglikelihood, logjoint │
│ │
│ Summary │
│ param mean std mcse ess_bulk ess_tail rhat q5 … │
│ dist.mu 1.8216 0.0387 0.0016 562.4674 774.2038 1.0005 1.7594 … │
│ dist.sigma 0.6718 0.0243 0.0011 528.1686 822.6892 1.0026 0.6335 … │
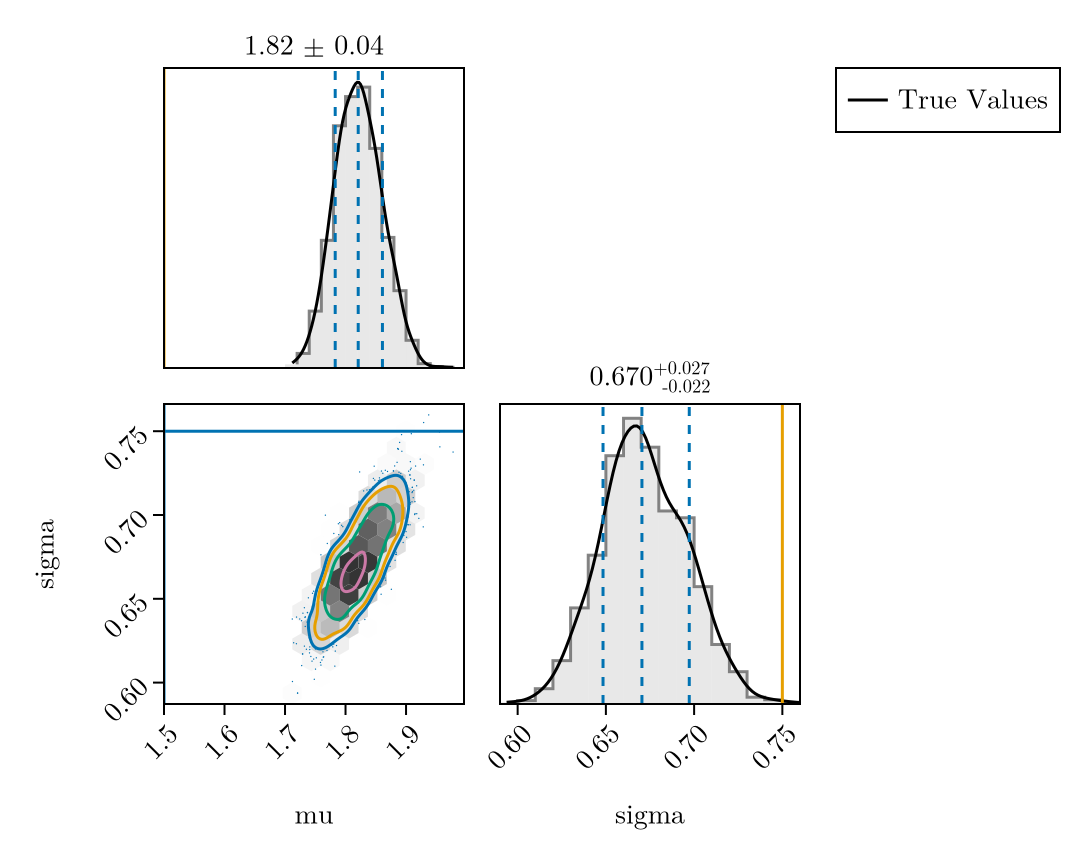
╰──────────────────────────────────────────────────────────────────────────────╯Lets plot the posterior compared to the true values again. to_submodel() automatically prefixes the LHS name to all variables in the inner model (so mu becomes dist.mu). Using FlexiChains' Prefixed wrapper in plot_fit_with_truth handles that transparently, so the same helper works for both the plain prior chain and the prefixed posterior chain.
plot_fit_with_truth(
interval_only_fit,
(; mu = meanlog, sigma = sdlog)
)
Fitting the double censored model
Now we'll fit the full model that accounts for the censoring process. Since the CensoredDistributions_model was defined earlier and used for simulation, we'll reuse it for fitting. Here we fix the censoring windows and observation time based on the observed data and then condition on the weighted observations.
CensoredDistributions_mdl = @with simulated_counts begin
@chain base_model begin
fix((
@varname(pwindows) => :pwindows,
@varname(swindows) => :swindows,
@varname(obs_times) => :obs_times
))
condition(
obs = (values = :obs, weights = :n)
)
end
end;
CensoredDistributions_mdl()(values = [8.0, 3.0, 6.0, 3.0, 9.0, 0.0, 4.0, 7.0, 6.0, 4.0 … 8.0, 9.0, 1.0, 0.0, 1.0, 1.0, 11.0, 0.0, 9.0, 0.0], weights = [3, 7, 6, 13, 4, 11, 16, 2, 18, 3 … 1, 1, 2, 1, 1, 2, 2, 1, 3, 1])Now we fit the model to recover the true parameters from the synthetic data we generated earlier. This demonstrates the package's ability to perform accurate parameter recovery when the censoring process is properly modelled.
CensoredDistributions_fit = sample(
CensoredDistributions_mdl,
NUTS(; adtype = AutoMooncakeForward()), MCMCThreads(), 1000, 4;
chain_type = VNChain
);
summarystats(CensoredDistributions_fit)╭─FlexiSummary (9 statistics) ─────────────────────────────────────────────────╮
│ iter collapsed │
│ chain collapsed │
│ ↓ stat = [mean, std, mcse, ess_bulk, ess_tail, rhat, q5, q50, q95] │
│ │
│ Parameters (2) ── AbstractPPL.VarName │
│ Float64 dist.mu, dist.sigma │
│ │
│ Extras (14) │
│ Float64 n_steps, is_accept, acceptance_rate, log_density, │
│ hamiltonian_energy, hamiltonian_energy_error, │
│ max_hamiltonian_energy_error, tree_depth, numerical_error, │
│ step_size, nom_step_size, logprior, loglikelihood, logjoint │
│ │
│ Summary │
│ param mean std mcse ess_bulk ess_tail rhat q5 … │
│ dist.mu 1.5065 0.0412 0.0014 940.7068 1066.8928 1.0004 1.4449 … │
│ dist.sigma 0.7630 0.0330 0.0011 929.2041 1037.4597 0.9998 0.7135 … │
╰──────────────────────────────────────────────────────────────────────────────╯And the corresponding pair plot with the true parameters overlaid:
plot_fit_with_truth(
CensoredDistributions_fit,
(; mu = meanlog, sigma = sdlog)
)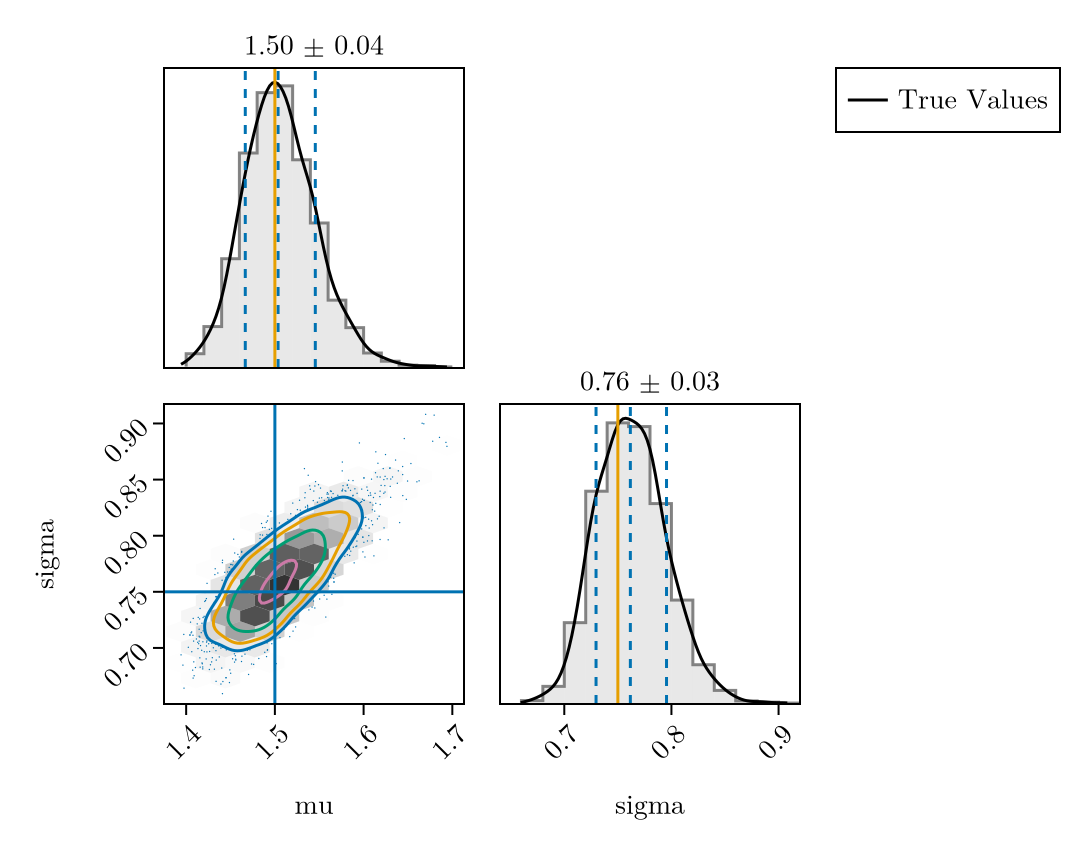
We see that the model has converged and the diagnostics look good. We also see that the posterior means are near the true parameters and the 90% credible intervals include the true parameters.
Working with FlexiChains output
Because we asked Turing to return a VNChain, the posterior is keyed by VarNames rather than flattened Symbols. That makes it easy to pull out specific quantities without string munging. For example, we can list the parameters in the chain directly:
parameters(CensoredDistributions_fit)2-element Vector{AbstractPPL.VarName}:
dist.mu
dist.sigmaWe can also compute per-parameter summaries by passing the chain to Statistics functions that FlexiChains extends. Here we ask for the posterior mean of each parameter:
mean(CensoredDistributions_fit)╭─FlexiSummary ────────────────────────────────────────────────────────────────╮
│ iter collapsed │
│ chain collapsed │
│ stat collapsed │
│ │
│ Parameters (2) ── AbstractPPL.VarName │
│ Float64 dist.mu, dist.sigma │
│ │
│ Extras (14) │
│ Float64 n_steps, is_accept, acceptance_rate, log_density, │
│ hamiltonian_energy, hamiltonian_energy_error, │
│ max_hamiltonian_energy_error, tree_depth, numerical_error, │
│ step_size, nom_step_size, logprior, loglikelihood, logjoint │
│ │
│ Summary │
│ param │
│ dist.mu 1.5065 │
│ dist.sigma 0.7630 │
╰──────────────────────────────────────────────────────────────────────────────╯and the rhat convergence diagnostic:
rhat(CensoredDistributions_fit)╭─FlexiSummary ────────────────────────────────────────────────────────────────╮
│ iter collapsed │
│ chain collapsed │
│ stat collapsed │
│ │
│ Parameters (2) ── AbstractPPL.VarName │
│ Float64 dist.mu, dist.sigma │
│ │
│ Extras (14) │
│ Float64 n_steps, is_accept, acceptance_rate, log_density, │
│ hamiltonian_energy, hamiltonian_energy_error, │
│ max_hamiltonian_energy_error, tree_depth, numerical_error, │
│ step_size, nom_step_size, logprior, loglikelihood, logjoint │
│ │
│ Summary │
│ param │
│ dist.mu 1.0004 │
│ dist.sigma 0.9998 │
╰──────────────────────────────────────────────────────────────────────────────╯Finally, because the chain is keyed by VarName, we can index into it with a Prefixed wrapper to recover the raw samples for a single parameter as a matrix of (iter, chain):
mu_samples = CensoredDistributions_fit[Prefixed(@varname(mu))]
size(mu_samples)(1000, 4)